今天看的论文还是与Hand Pose Estimation相关,链接如下:
Paper: CrossInfoNet: Multi-Task Information Sharing Based Hand Pose Estimation
Abstract
与之前的网络不同,这篇网络是基于Depth map的,并将手势识别任务分成两个,分别是手掌姿态识别的子任务,和手指识别的子任务(这点我感觉还蛮新奇的,感觉以后可以用到Salient Detection里面试试),并采用了一种两路交叉连接网络,来在子任务之间进行信息的互相补充(这一点也挺有趣的,可以考虑放到Fuse模块),并且本文还提出了一种热力图引导式的特征提取结构,来提取出更好的特征。
另:由于3D的信息会有过多的参数,所以本文尝试着用2D CNN,从2D信息(Depth Map)中,提取出更多的信息,
Contribution
- 提出了一种新的多任务的手势识别网络,首先用一个分级网络将任务分成手掌节点识别,和手指节点识别两个子任务子任务,另外通过交叉连接,生成的attention mask,能够引导其中一支集中在手掌节点识别,而另一支集中在手指节点识别上。
- 提出了一种Heat-Map引导式的特征提取方式,在没有失去端到端训练优势的同时,能从该引导任务中提取出更多的有效信息。
- 用多个baseline证明了该解决办法的可行性
Proposed Method Details
提出的网络图如下: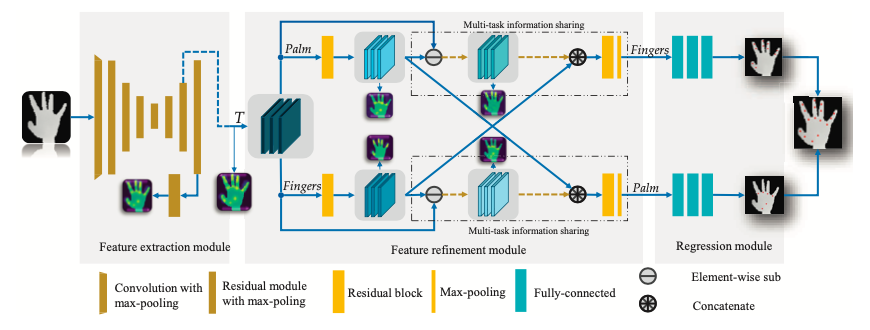
首先,第一部分就是初始的特征提取模块,本文通过融入热力图来更好的引导或限制网络学习到更好的特征图,第二部分就是特征优化部分,这部分由两部分组成(手掌和手指),其中有交叉模块来有效的提取出有效信息,而最后一部分就是联合的坐标预测模块。
Heat-map guided feature extraction
这部分的结构如下: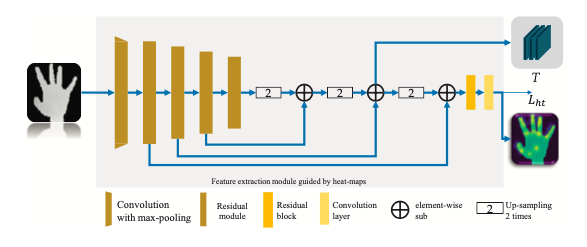
本文中说一个普通的Shallow的网络通常提取不出一个满意的特征,所以提出了这么一个新颖的特征提取并优化网络(Backbone是ResNet-50),如图所示,本文是用来特征金字塔来融合不同的特征层,并用Feat-Map仅来引导特征提取部分,并不会传递到下一子模块。最终生成的特征T有256个channel,残差模块的Kernel Size是3×3,而max-pooling的Kernel Size是2×2,stride是2。
Baseline feature refinement architecture
Baseline结构如下: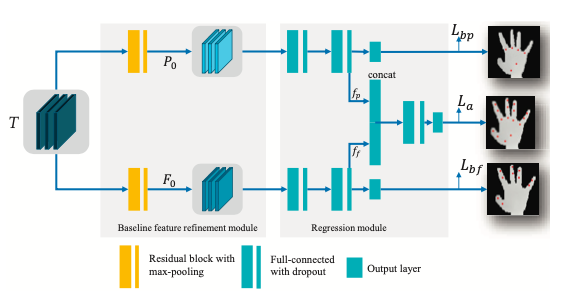
正如之前所说的,由于手掌部分相比手指部分有更小的活动空间,所以其实这两部分的回归复杂度是不同的,所以本文用两个不同的参数集来表示手掌和手指,这样才能回归的更加容易。所以才做独立的branch,并且采用了一个分层次的网络结构,即之前生成的特征T,首先分别用来生成手掌或手指的内部(intrinsic)特征,最后两个branch的全连接层$f_{p}$和$f_{f}$的输出再被concat到一起来预测所有的结点坐标,以上就是Baseline网络。
New feature refinement architecture
baseline的问题就是,两路信息都是各自独立的,他们之间的信息交流太少了,然而其实两路的信息中,都会有相对于这一路是噪声,但相对另一路是有利的信息,所有为了有效的利用这些有利的”Noise“,提出了接下来的这个网络: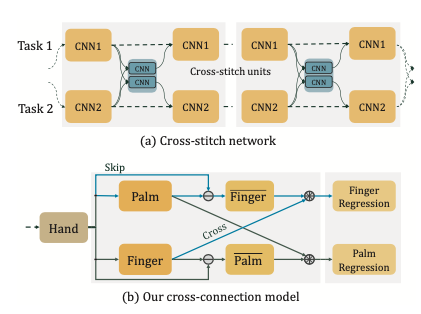
现有的方法比如上图(a)所示的那样,叫作Cross-stitch Network,它使用了多重的交叉编制单元来将其他task的学习到的知识(knowleage)进行懒融合(Lazy Fusion),但是正如它的名字显示的那样,是懒融合,也就是没有考虑两个task之间的相似性和关联。
本文所希望做到的就是,主动地引导子任务,告诉它们怎么和其它子任务交流,上图(b)就是本文提出的引导式多任务信息分享机制,它首先使用跳连(Skip Line),来将手掌和手指分开,及将手掌特征从全局的手特征中提取(Subtract)出来,得到手指特征,然后使用交叉连接,将两路Branch提取出来的手指特征Concat到一起,这样能减少手掌特征的干扰,并再一次enhance手指的特征,and vice versa。
完整的refinement模块如下: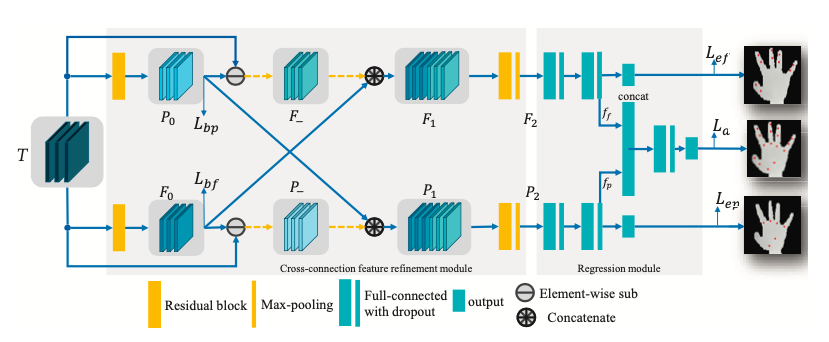
以上路Branch为例,初始特征$T$同时有手掌和手指特征,如果用训练出的手掌为主的特征${p}_{0}$来减去$T$,就能得到残差的手指特征${F}_{-}$,可以认为是手指的’attention mask‘,这个特征对于手掌特征来说可能是噪声,但是对手指特征有利,能引导着这手指这一路来提取出更好的特征,反之亦然。最后通过交叉连接,把${F}_{-}$和${F}_{0}$进行Concat融合,就能得到${F}_{1}$的更好的特征,输入到后面的网络。
Loss Functions
这里有两部分,对于最后的输出,使用MSE,而同时也使用了heat-map,作为一个引导,引导网络更好的进行全局特征提取,这部分的loss可以写为:
其中${A}$表示手的总Joint数量,$H_{n}^{a }$和$H_{n}^{a}$分别表示heat-map在*joint $n$上的的真值和估计值。
另外refinement部分,最开始的${f}_{0}$和${p}_{0}$也需要有引导,所以也有以下两个loss:
最后的预测阶段也有三个Loss,因为要分别预测,再联合预测
所以最后的总Loss可以写成:
$\alpha$ 和 $\beta$分别设置为0.01和1。
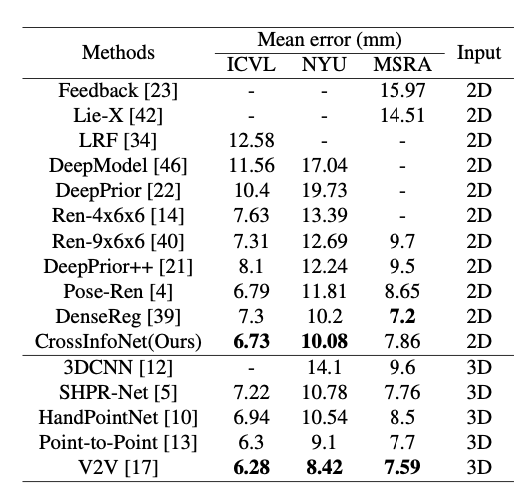
Comparisons with state-of-the-art methods
最后与其它方法的比较如下: