虽然看过的姿态识别的论文不多,但是发现在这些网络里面,Stacked Hourglass Network这个网络模块出现的频率相当高,所以谷歌了一下,发现这里面能学习借鉴的地方相当多,所以感觉也可以总结一下这个模块。
Stacked hourglass networks for human pose estimation
这篇论文是第一个将hourglass network引入human pose estimation,这个网络的特征,就是不断重复自下而上(bottom-up)、自上而下(top-down)过程,以及运用中间监督(intermediate supervison),即不断地pooling and upsampling,这样一来,特征在不同scale得到了联合,从而可以更好地捕捉到身体不同部位的空间联系(spatial relationship)。
之所以叫这个网络为Hourglass,首先是因为这个网络是对称的,bottom-up过程将图片从高分辨率降到低分辨率,top-down过程又将图片从低分辨率升到高分辨率,所以最后的网络图就把它画成了沙漏的形状。结构如下: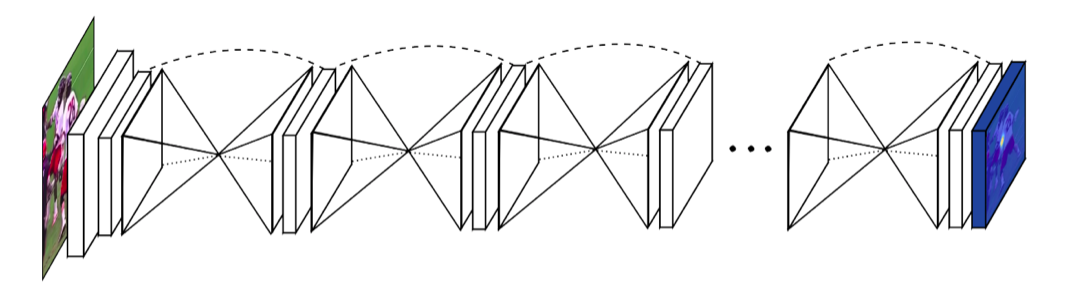
Hourglass Module
在像人体姿态估计这种领域,各个尺度下的特征都是必要的,比如要捕捉脸,手这样的结构时,需要对局部特征进行分析,但是对整个人体的姿态进行分析的时候,又需要对整体的特征进行分析,所以这个沙漏网络就是这样,如下图所示: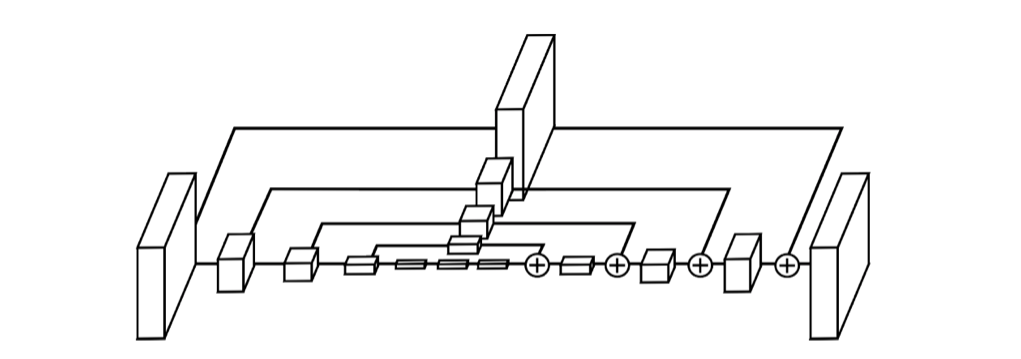
通过多个Pipeline,分别单独处理不同尺度下的信息,在网络的最后再Fuse这些特征,
Network Detail
最基础的模块就是残差模块(Residual Module)
上图中的每个方块都是由以下结构中的残差块组成的: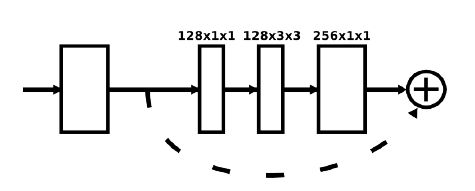
更加详细的结构可以看成: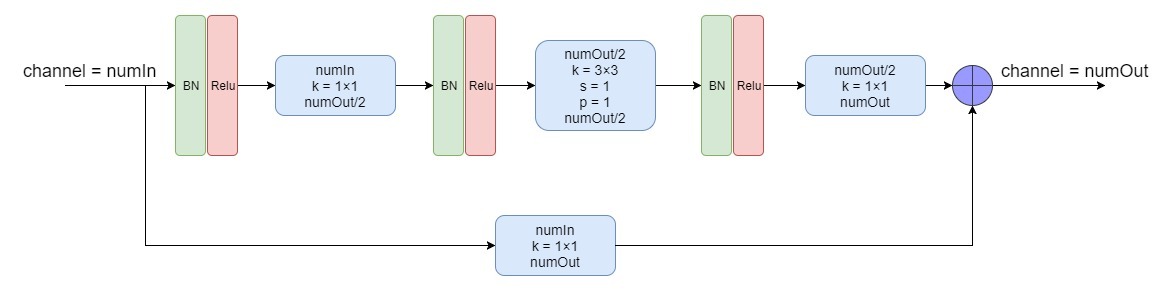
这就是Res Module,也就是最基础的模块
Hourglass Module
基础的沙漏模块结构如下: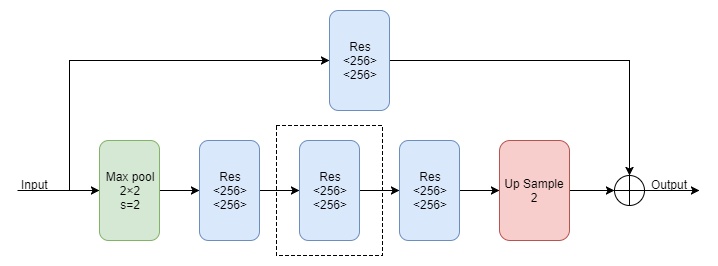
其中Max pool代表下采样,Res代表上面介绍的Residual Module,Up Sample代表上采样。图中的结构就是一阶的Hourglass Module,如果要增加一阶,就是要把图中的虚线框替换成一阶的Hourglass Module,那么四阶的如下: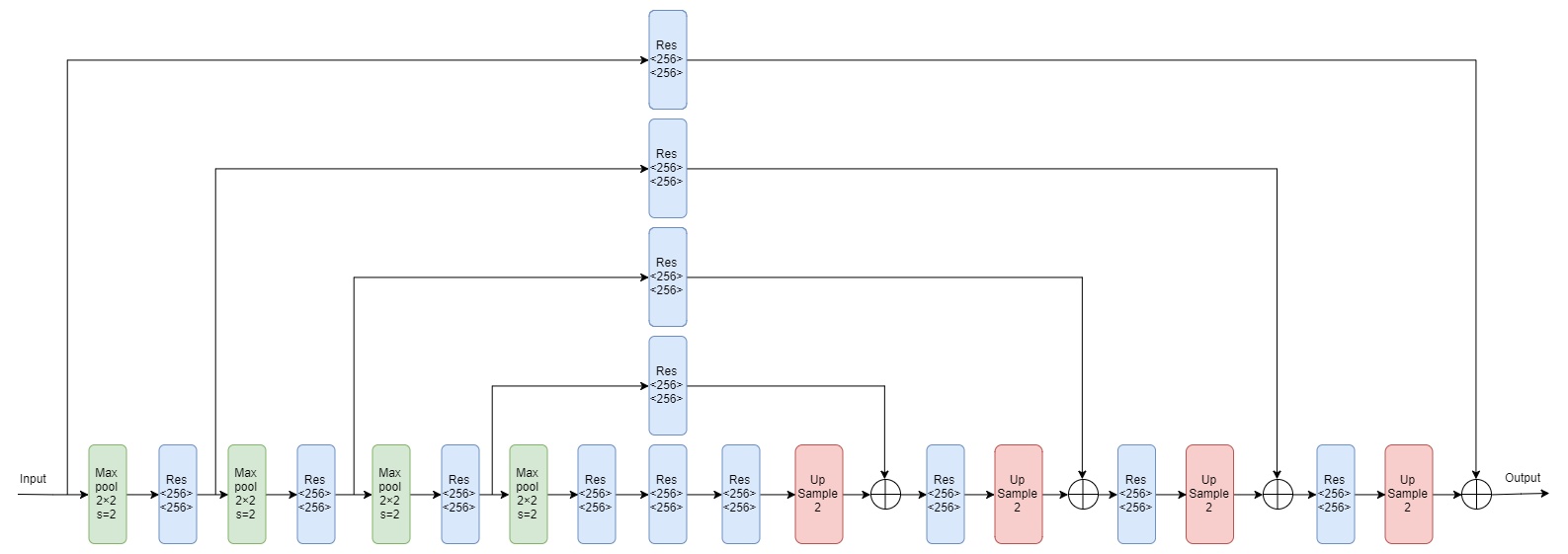
总的来说:网络输入的图片分辨率为256×256,但是在hourglass模块中的最大分辨率为64×64,所以在整个网络开始之前,要首先经过一个7×7的stride为2的卷积层,之后再经过一个残差块和Max pooling层使得分辨率从256降到64。总结构如下图所示:
图中的4阶Hourglass Module就是前面讲的4阶Hourglass Module,而图中的渐变红色块就是加入了中间监督的地方,即在此处使用loss函数。
Intermediate Supervison
本文中提到,要让这个结构有效的关键就是要使用中层监督,对每个Hourglass Module进行预测,并根据Heat maps计算loss。
而至于中间监督的位置,作者在文中也进行了讨论。大多数高阶特征仅在较低的分辨率下出现,除非在上采样最后。如果在网络进行上采样后进行监督,则无法在更大的全局上下文中重新评估这些特征;如果我们希望网络能够进行最佳的预测,那么这些预测就不应该在一个局部范围内进行。
由于hourglass模块整合了局部和全局的信息,若想要网络在早期进行预测,则需要它对图片有一个高层次的理解即使只是整个网络的一部分。最终,作者将中间监督设计在如下图所示位置:
关于中间监督的位置,作者也进行了对比实验,结果如下图所示: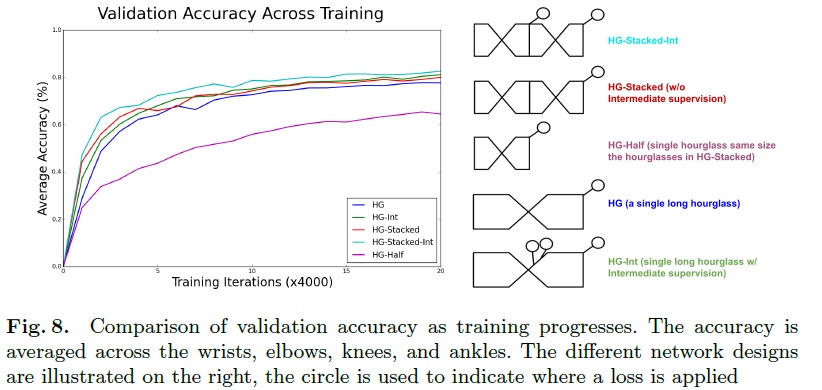
可以看到结果最好的是HG-Int,即在最终输出分辨率之前的两个最高分辨率上进行上采样后应用中间监督。
Training Details
作者在FLIC和MPII Human Pose数据集上进行了训练与评估。这篇论文只能用于单人姿态检测,但是在一张图片中经常有多个人,解决办法就是只对图片正中心的人物进行训练。将目标人物裁剪到正中心后再将输入图片resize到256×256。为了进行数据增量,作者将图片进行了旋转(+/-30度)、scaling(.75-1.25)。
网络使用RMSprop进行优化,学习率为2.5e-4. 测试的时候使用原图及其翻转的版本进行预测,结果取平均值。网络对于关节点的预测是heatmap的最大激活值。损失函数使用均方误差(Mean Squared Error,MSE)来比较预测的heatmap与ground truth的heatmap(在节点中心周围使用2D高斯分布,标准差为1)
Thoughts and Further Analysis
这篇文章提出的时间较早,在那之后,又有很多基于这篇文章上的改进版本被提出来,比如说原网络中的短接层,可以换成不同的卷积核同时进行卷积,比如Inception模块: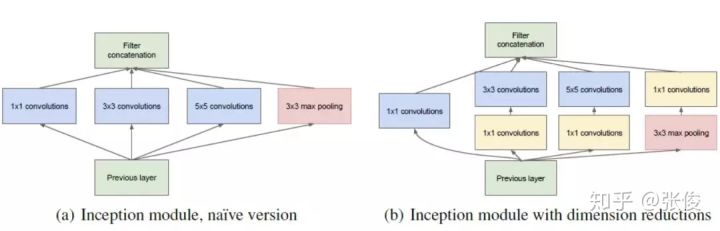
通过使用不同大小的卷积核以及 1*1 的卷积使得网络能够捕捉不同分辨率的特征,并减少参数数量。
另外基于ResNet上改进的ResNeXt:
将初始的输入分裂成多条分支进行卷积,其中每条分支的卷积核大小都是一样的,但能相对ResNet进一步减少参数。
再或者,直接用空洞卷积代替上采样、下采样部分: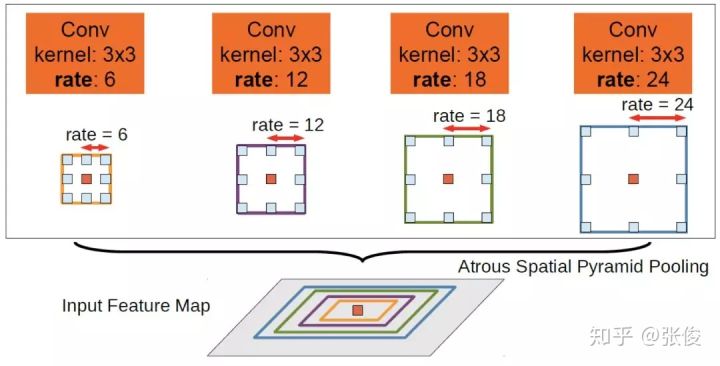
也可以获得多尺度的特征,空洞卷积是通过使用具有间隔的卷积核在特征图上进行卷积从而避免对原特征图进行下采样的步骤。
再或者,如下图中的四种特征金字塔模块所示: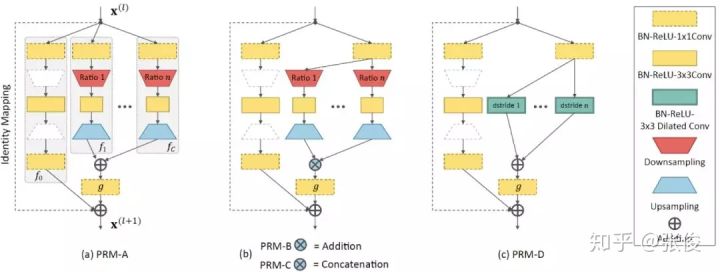
PRM-A 是在原先的残差模块的分支基础上,直接增加多个分辨率的分支,其分辨率的不同主要是通过下采样实现的,而由于残差模块的结果需要将不同分支的结果相加,因此下采样后的特征要通过上采样恢复原来分辨率。
PRM-B 则是将 PRM-A 中不同分辨率的分支开始的 1*1 卷积进行参数共享,从而减少参数数量。
PRM-C 则是将 PRM-B 中多分辨率特征的相加改为了串联,由于串联后的特征通道数与原来不同,因此可能需要再进行一个 1*1 的卷积对齐特征通道后再与原特征相加。
PRM-D 则是使用空洞卷积代,替下采样和上采样得到多尺度的特征。
实验结果如下: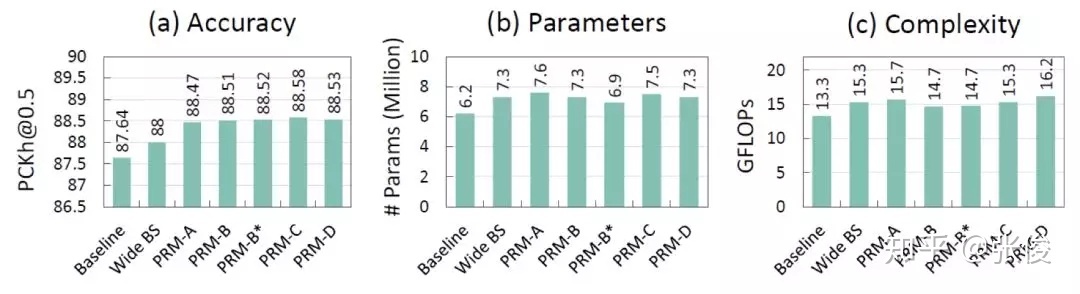
除了上述的改进,本文作者还提到原始的残差模块有输出方差积累的问题,当堆叠多个残差块时,将原始特征直接与卷积后的特征相加时会有较大的方差,通过对原始特征添加一个 Bn-ReLu-Conv 操作可以较好的控制这个问题: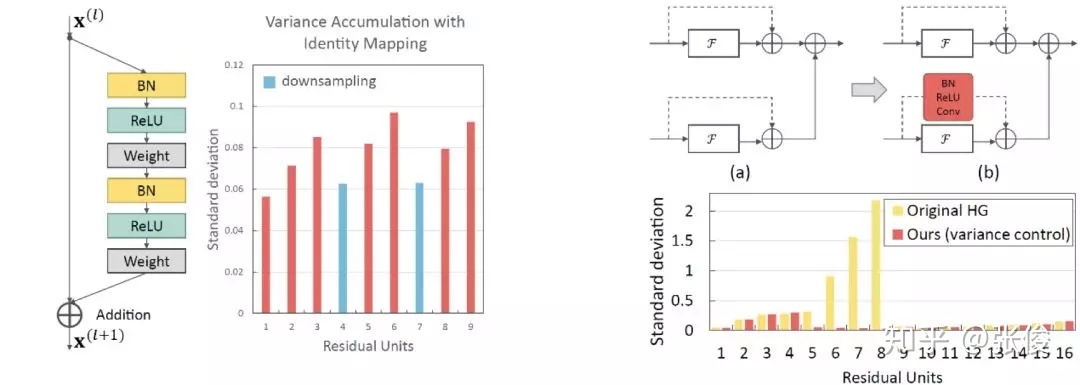
其他的算法,比如说: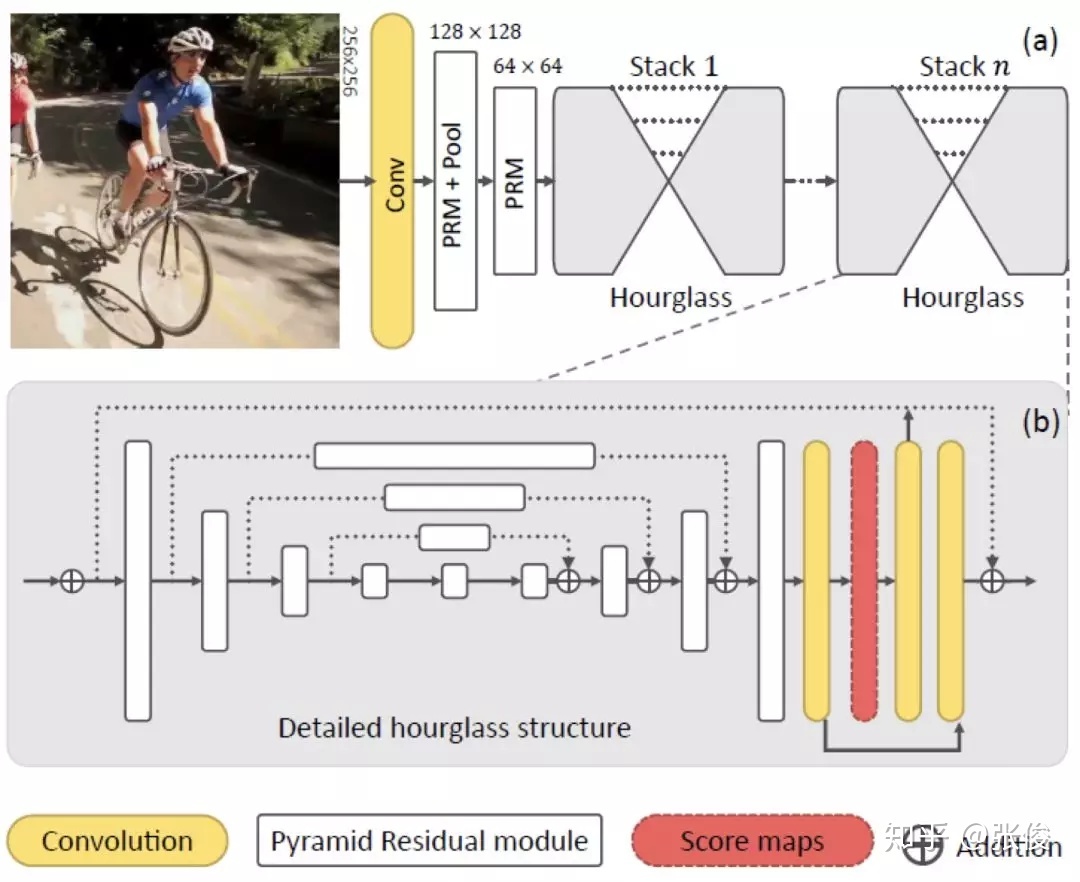
使用 Stacked Hourglass Network 的基本框架,但将其中的残差模块都替换成了上述特征金字塔模块PRMs。