看了几篇手势识别的A类论文之后,感觉可以看看实验室的成果了,所以今天开始看看实验室的基于EMG的手势识别论文了,论文名称及链接如下:
Abstract
在肌肉-计算机界面(muscle-computer interface (MCI)),深度学习能充当一个分类器的功能,用于从接收到的表面肌电信号(surface electromyography (sEMG) signals)中识别出手势。本文主要是基于这样的一个现象,即,在特定的手部运动中起到重要的作用的仅仅是手臂上的一小部分肌肉如下图所示: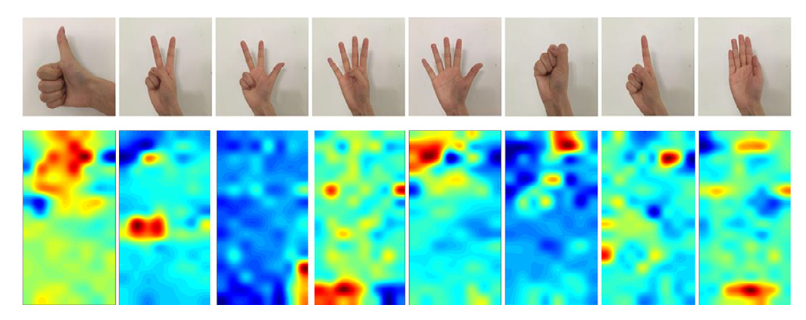
所以本文就提出了一个多流(Multi-Stream)的CNN结构(divide-and-conquer),通过学习单独的肌肉与特定的姿势之间的关系,来提高识别准确率,网络有两部分,即多流的(均等)分解(multi-stream decomposition)网络和融合(fusion)网络。
Background
传统的基于sEMG的姿态识别系统通常都有这样几个步骤: 信号检测(signal detection), 信号预处理和分割(signal preprocessing and segmentation), 特征提取(feature extraction), 和姿态识别分类(gesture classification),但是其中的特征都是人类专家设计出来的,而识别部分则使用比如隐马尔科夫模型(Hidden Markov model(HMM))、高斯混合模型(Gaussian Mixture models(GMM))和支持向量机(Support Vector Machine(SVM))。所以本文就提出能否用深度学习来进行特征的提取和分类。
另外本文还基于:对于每个特定的姿势,只有一部分表面肌电信号(sEMG Channels(Electrodes))或者一小部分肌肉与之有很强的联系,而不是所有的表面肌电信号
Proposed multi-stream CNN framework
提出的网络如下: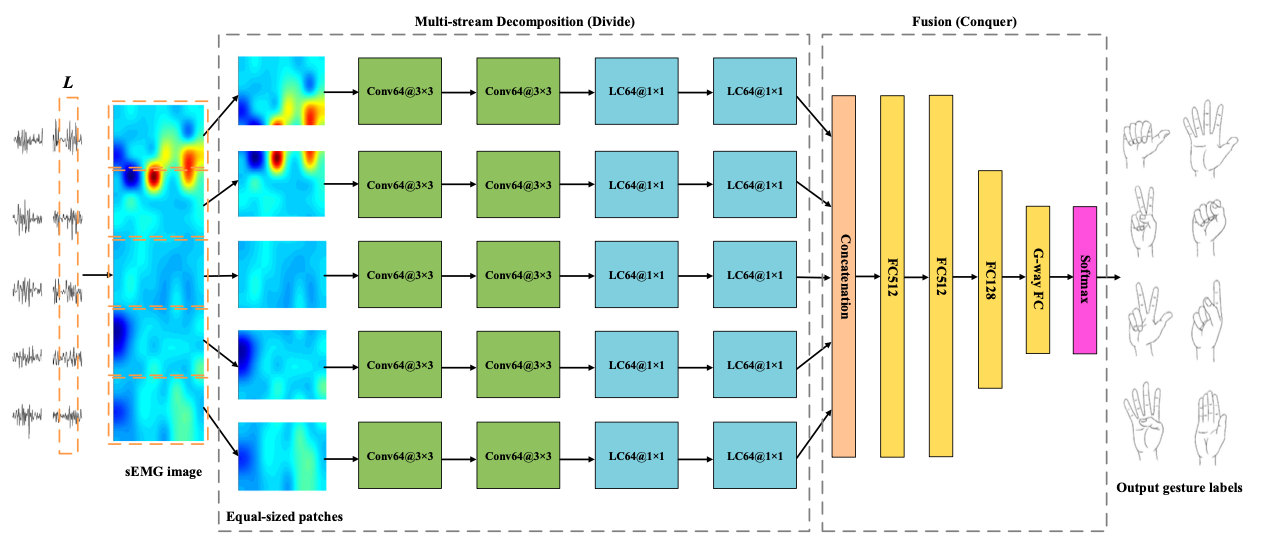
网络首先使用sEMG image $\boldsymbol{x} \in \mathbb{R}^{W \times H}$作为网络的输入,其中$W$和$H$分别是输入图片x的宽和高,而且x的组成取决于用的是哪种类型的表面肌电信号。
同样的对于多路网络也有很多种,比如强度(Intensity)和深度(depth),高分辨率和低分辨率,手特征和身体特征,而多路中的Divide-and-conquer也有很多种,比如在采样空间(Sample Space),将输入实例分成小子集,再递归的客服他们,另外也有在特征空间的(Feature Space),即原有的特征被分解成一些小子集(线性变换),再将分解的子集分别用来训练局部的分类器,最后这些局部的分类器的输出再被融合到一起得到最后的结果。
本文采用了前者,将$\boldsymbol{x} \in \mathbb{R}^{W \times H}$分解成 M 个等分的patch,M取决于用了多少个电极,分解的patch再被输入到各自的自网络。而融合部分,学习到的所有M路的特征被融合到了一个特征图$\boldsymbol{s} \in \mathbb{R}^{W \times H}$,与原始的sEMG大小相同,然后将s批正则化处理,并输入到一个融合的网络里面得到姿态识别结果。