这篇文章也是现在的这个实验室研究的,关于EMG的手势识别论文了,论文名称及链接如下:
Paper: Semi-Supervised Learning for Surface EMG-based Gesture Recognition
Abstract
本文首先提出,现有的深度学习方法都需要一个很强监督的学习算法和一个很大尺度的sEMG标注数据,而现有的与sEMG相关的手势识别数据集的数量和质量都太差了,而本文发现,其实sEMG信号和数据手套(Data Glove)在时间的空间上有一定的联系,这能给网络提供一种隐式的监督,所以本文设计了一种半监督的孪生网络(Siamese architecture),即,本文使用了一种辅助的任务来帮助学习:通过预测两个连续sEMG帧的时间顺序,然后选择性的预测其中一个sEMG帧的3D手姿势。
Introduction
现有的方法为了增加数据集的质量,有的方法选择了数据增强,或者将sEMG分割,只使用一小部分的原信号,但是现有数据还有一点不足,就是,记录下来的采样数据也许并不完美地和label匹配,因为人会有一定的反应时间,并且人会有一定的过渡动作。再加上数据集的质量不高,纯粹的监督学习就不能完全发挥作用,这种情况下,就可以考虑半监督(Semi-Supervised Learning)。
Contribution
半监督通常需要多个学习任务来辅助。所以本文的贡献在于:提出了一个半监督框架来训练一个分类器去发现信号之间的时间连贯性,而这个任务能辅助主任务。
即,用一个ConvNet,基于sEMG信号的一帧,来同时预测三个目标:手的姿势,两个连续sEMG帧的时间顺序,以及(可选)3D手姿势的数据。而后两者需要动态数据(从sEMg信号中获得)和手运动的形状(从数据手套中)获得。
本文的网络如下: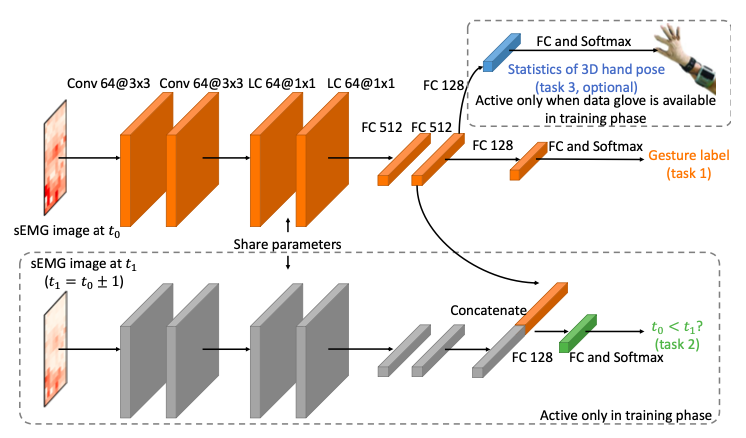
前六层的参数共享,不同的颜色代表不同的任务。
Proposed Method Details
本文中说到,之所以使用一个相邻帧的时间的顺序的预测,是因为它在一定程度反应了肌肉的启动(Firing)顺序,这与速度和姿势的丰富度是没有太大关系的,本文假设这个预测任务是需要隐式的知道肌肉活动的动态特征信息的。
本文选择3D姿态数据预测作为第三个任务,是因为3D手势序列,直接决定了识别到的手势,并且相对姿势label来说有更强的监督力度。但第三个任务是可选的,因为用来采集3D真值的数据手套有时可能没有。
Problem Statement
让$\mathcal{L}=\left\{\left(\mathbf{x}_{i}^{l}, y_{i}\right)\right\}_{i=1}^{N_{l}}$表示有label的训练数据,$\mathcal{U}=\left\{\mathbf{x}_{i}^{u}\right\}_{i=1}^{N_{u}}$表示没有label的帧数据,
而最后的目标就是优化:
这个方程了。
本文设计了一个ConvNet来根据上式建立模型,在训练阶段,给定sEMG图片,最后在三个子任务上输出三个预测。
具体的${L}_{l}$可以写为$L_{l}(\mathbf{x}, y | \theta)=-\sum_{i=1}^{G} \mathbf{1}_{i}(y) \log f_{\theta}^{i}(\mathbf{x})$
Temporal Order Prediction of sEMG frames
sEMG帧的预测问题可以定义为一个二元分类问题,其中分类器为:
来预测两帧之间的时间先后顺序。
3D Hand Pose Statistics Prediction
与直接从sEMG图片中回归出结点角度和位置不同,本文显式的定义了手的姿态种类,并且确切的将预测问题定义为一个分类问题,这是因为对于每个节点来说,直接从sEMG映射到节点角度是很困难的,然后在计算Loss时就更难平衡好不同点之间的权重。
同样的,本文也将3D手姿势的数据预测看成一个分类问题,其中训练了一个分类器$h_{v}(\mathbf{x} | \Theta)=\hat{h}_{v}\left(h_{c}\left(\mathbf{x} | \theta_{c}\right) | \theta_{v}\right)$来预测给定x的手姿态label。
另外,训练集的3D手姿势首先用K均值方法聚类,然后每个pose都标上Label,且聚类的个数应该比姿势的个数多,因为本文需要为手的姿态(Hand Pose)labels提供比手势Labels更加细颗粒度的监督。