实验室给了两个方向,但是还没有确定哪个方向,所以两个方向的论文都要看,所以从今天开始打算看另一方向的论文,大概看了看,是物体识别方向的论文,怎么感觉这个方向会更加熟悉一些呢。。。
今天看到这篇论文如下:
paper: T-CNN: Tubelets with Convolutional Neural
Networks for Object Detection from Videos
Abstract
最近几年,物体检测的State-of-the-art越来越好,从GoogleNet和VGG,到新出现的R-CNN,Fast R-CNN,但是尽管它们在静止图像上取得了较好效果,但是这些方法都不是专门为视频的物体检测设计的,视频里面的时间的信息及上下文信息都没有好好的利用。而本文就提出了一个新的深度学习网络,能从视频中获到的tubelets中提取出时间和上下文信息,并纳入到神经网络的学习中,比直接用静止的物体检测方法来检测视频要有更好的效果。
Introduction
如果要专门为视频设计网络,其中的关键点之一就是检测的结果的框的定位(bounding box location)和检测置信度(detection confidences),在短时间内不会有较大的变化。
针对这一点,有几种方法,其一是将检测的结果传递到相邻的帧,来降低结果突然变化的幅度,比如由于模糊,物体姿态特殊(moving blur, bad poses, or lack of enough training samples under particular poses)等原因没有检测到的,可以用这个方法增加其置信度,另外由该方法导致产生的重复的框,可以用non-maximum suppression (NMS)方法去除。
另一方法就是提高时间上的一致性来给检测结果增加一个长期的(long-term)的限制,如下图(a)所示: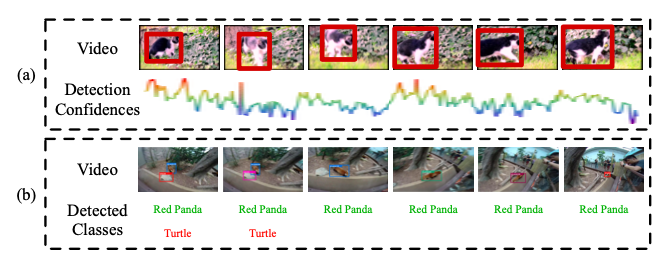
同一物体的Bounding Box的检测置信度在一段时间内会有较大的变化,所以可以将这个Tubelets看成一个单元(Unit),给它加上一个长期的限制,比如,如果一个tubelet的大多数的Bounding Box都有较高的检测置信度,那么那些置信度较低的帧上值就应该提高一些来满足一致性。
针对视频的检测,另一关键点就是对于上下文信息的处理,尽管普通的物体检测方法也会利用上下文信息,但是视频里的上下文信息会更加丰富(a collection of hundreds of images),因为有时候单帧里的上下文信息有时候不够用于区分识别错误的物体(False Positice),所以如果识别出了一段视频里的高置信度的majority,那么false positive将被认为是outliers,并被抑制住。
Proposed Method Details
本文提出的网络图如下所示: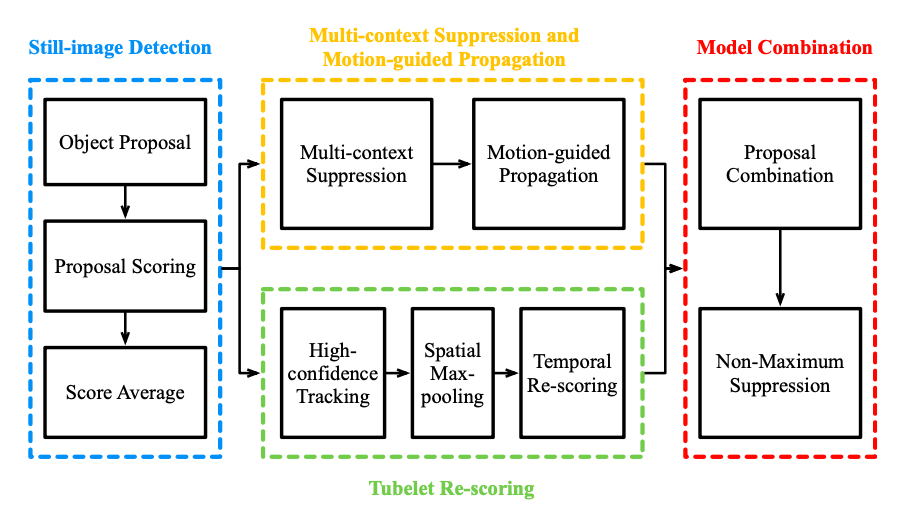
其中该任务叫作object detection from video(VID) task,与object detection task(DET)类似,从200类中提取出了30类来做视频的识别,主要就是要产生$\left(f_{i}, c_{i}, s_{i}, b_{i}\right)$,表示帧的索引,类别的label,置信度,以及bounding box。
其中主要有四部分:
- still-image detection
- multi-context suppression and motion-guided propagation
- temporal tubelet re-scoring
- model combination
Still-Image Detection
本文的静止图片物体识别使用了两个框架:DeepID-Net和CRAFT,分别是R-CNN和Fast R-CNN的拓展,而两个任务的结果将被分别用于后面的网络。
Multi-Context Suppression
首先将所有检测到的置信度由高到低排列,然后分为高置信区和低置信区,而低置信区的分数将被压制,即减少(False Positives)。
Motion-guided Propagation
在静止图像检测时,有些物体将会由于模糊等因素而没有被检测出来,这时候动作(time)信息将能帮助解决这一点,将检测结果送到邻近帧来减少(False Negatives)
Temporal tubelet re-scoring
由之前的从所有静止图片中检测出来的高置信结果,本文首先使用追踪算法,从中获得bounding boxes序列,也就是Tubelets,然后根据它们的检测分数的数据,将Tubelets分类成正样本和负样本,正样本的分数将被提高,负样本将被降低,以增大Margin。
Model combination
两个网络(DeepID-Net和CRAFT)都经上下两个模块产生的结果,首先都映射到[0, 1]空间下,并通过NMS过程融合到一起(IOU Overlap设置为0.5),得到最后的结果
Thoughts
总的来说,本文根据视频特征提出两个特征还是很有意思的,上下文信息用来去除错误的检测结果,而时间信息用来恢复没检测到的,但是缺点就是不是端到端,不好训练,不过毕竟是2016年的文章,之后应该会有人提出改进的措施。