今天看的这篇文章是物体识别的,链接如下:
paper: M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
Abstract
特征金字塔结构被广泛用于单Stage和双Stage的物体探测(Object Detector),能达到很好的效果,但是由于它只是简单的根据固有的多尺度的,backbone的金字塔结构来构造特征金字塔(原本用于物体分类),所以有一定的局限性,本文就是提出了一个新的金字塔结构。首先把从Backbone中提取出来的多层特征融合到一起,然后将基础特征送到一个交替使用Thinned U模块和特征融合模块的Block,最后,将有等效大小的解码器集合在一起来构建一个针对物体探测的特征金字塔。
Introduction
图像金字塔(Image Pyramid)和基于输入图片的特征金字塔(Feature pyramid extracted from the input image)都能有很好的效果,但是它们由于设计过于简单,以及金字塔原本就不是针对物体探测任务,它们都有一定局限性,(比如高level特征更加容易区别,而低level会更加有助于物体定位)。所以本文的目标就是搭建一个更加有效的在各个尺度上的特征金字塔。
Proposed Method
M2Det大致的网络结构图如下: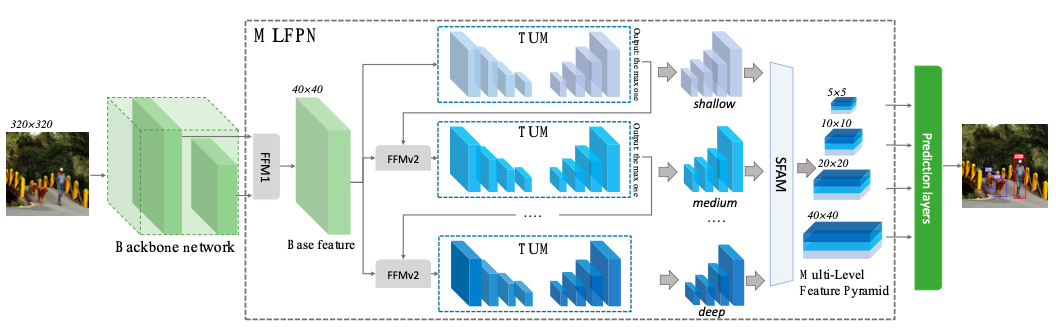
首先使用backbone网络和多尺度特征金字塔网络(Multi-Level Feature Pyramid Network (MLFPN)),从输入图片中提取出特征,然后与SSD类似,基于产生的特征产生紧密的(dense)bounding box,和种类分数,最后通过非最大值抑制(non-maximum suppression (NMS))操作来生成最后的结果。
其中MLFPN包括三个模块,特征融合模块,Thinned U模块和按比例的特征融合模块(Scale-wise Feature Aggregation Module(SFAM))
Multi-level Feature Pyramid Network
由上图可以发现,它只包含三个部分,和特征金字塔结构,其中多层次多尺度特征可以表示为:
FFMs
作为本文网络的融合模块,它使用1×1卷积层来压缩输入特征的通道并使用串联(concatenation)操作将特征图聚合到一起,具体如下图中的(a)和(b)中所示: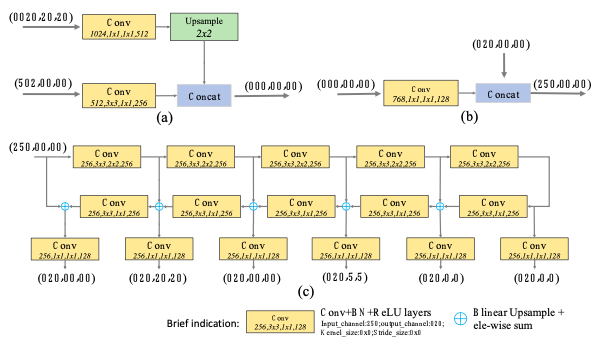
TUMs
如上图中的(c)所示:其中的编码器使用3×3卷积层(stride为2),而解码器将这些层的输出作为它的引用集(Reference Set)。
SFAM
SFAM的目标就是将TUMs生成的多层次多尺度的特征,融合进一个多层次的特征金字塔,具体的如下所示: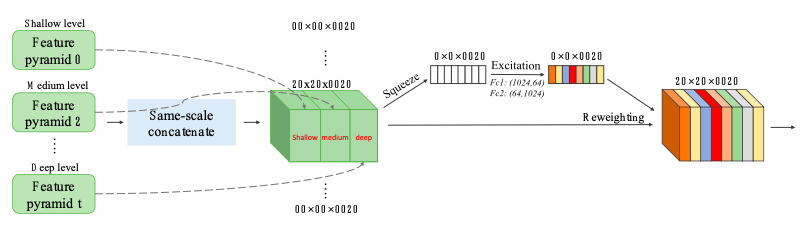
首先将等效大小的特征沿着通道(Channel)维度串联到一起,融合后的特征金字塔可以表示为$\mathbf{X}=\left[\mathbf{X}_{1}, \mathbf{X}_{2}, \ldots, \mathbf{X}_{i}\right]$,其中$
\mathbf{X}_{i}=\operatorname{Concat}\left(\mathbf{x}_{i}^{1}, \mathbf{x}_{i}^{2}, \ldots, \mathbf{x}_{i}^{L}\right) \in \mathbb{R}^{W_{i} \times H_{i} \times C}$。
然而简单的串联操作的适应性可能不是很强,所以在该模块后面,本文又使用了一个逐通道(Channel-Wise)的注意力机制来引导特征集中于最能受益(that can benefit most)的channel。而为了充分地捕捉逐通道的依赖,接下来通过两个全连接层来学习注意力机制:
而最后通过权重调整输入$X$和激励函数,得到最后的输出$s$:
其中:$\tilde{\mathbf{X}}_{i}=\left[\tilde{\mathbf{X}}_{i}^{1}, \tilde{\mathbf{X}}_{i}^{2}, \ldots, \tilde{\mathbf{X}}_{i}^{C}\right]$。