今天看的这篇文章还是物体识别的,链接如下:
paper: Fast Online Object Tracking and Segmentation: A Unifying Approach
这篇文章提出了一个网络,能同时实现视觉上的物体追踪和实时的半监督的视频物体分割,取名为SiamMask,除了简洁,灵活,并且速度很快,效果也很好。
Introduction
追踪(Tracking)能建立帧与帧之间的的物体匹配,所以它是视频应用中的基础任务(类似于显著性检测),比如自动监督(Automatic Surveillance)、自动驾驶(Vehicle Navigation),视频标记(Video Labelling)、人机交互(Human-Computer Interaction)和活动识别(Activity Recognition)。
而对于这些应用,最重要的就是能实现在线的(Online)追踪(不是简单的在线下找到帧与帧的关系,不管是之前的而是之后的,而是在视频正在播放的时候,就实时的给出结果,不依赖未来未知的可能出现的帧)。
与追踪类似,半监督的视频物体分割(Semi-Supervised Video Object Segmentation(VOS))需要估计任意物体在第一帧里面的位置,所以就需要一个二元mask,这样就需要大量的计算,所以现有的VOS一直都很慢。
而最近有提出一些基于Siamese网络的快速的追踪办法,基于这个,本文的目标就是在保留线下的可训练性和线上的快速识别以外,大量的增加目标物体的表达性(Representation),即效果。
为了达到这个效果,本文同时在三个task上训练了孪生网络,每个都用了不同的策略来建立目标物体和新的帧里面的候选区域的联系,其中一个就是在滑动框(Sliding Window Fashion)里面去测量目标物体和多个候选区域的相似性,而另两个任务就是为了优化这个结果:Bounding Box Regression和Class-agnostic Binary Segmentation,且只有在线下训练的时候才会需要二元label来计算loss。
Methodology
为了线上的可操作性和快速,本文使用了一个完全卷积的孪生网络,如下:
Fully-convolutional Siamese Networks
总的结构图为: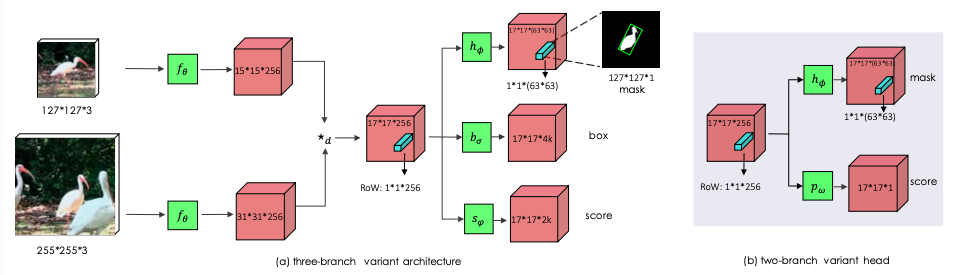
首先由z和x分别是w×h大小的在目标物体和最后一个估计的图像中间切出来的图像,就能产生两个互相联系的特征图:
SiamMask
最后就生成预测的mask:
其中Loss Function为:
除此之外,本文还增加了两个限制:
Thoughts
这篇博文主要从 Tracking 的角度来看待这个跟踪算法。提出一种多任务框架,来实现同时跟踪与分割,初步探索了目标的表达对跟踪结果的影响。具体效果如下图所示: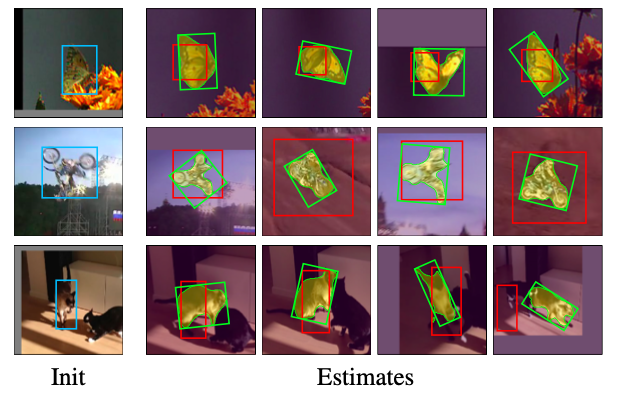
究其根本,就是在想怎么用更好的 Bounding Box 框柱物体,以适应物体的形变等导致的跟踪不准确的问题。当上一帧的跟踪结果靠谱时,那么当前帧就可以进行很好的采样,跟踪。作者在 Siamese Net based tracker 的基础上,进一步引入 Mask branch,得到分割结果。然后在此基础上,进行跟踪。这一步,其实相当于一定程度上解决了目标尺度变化的问题。
而分割模块的结构具体如下: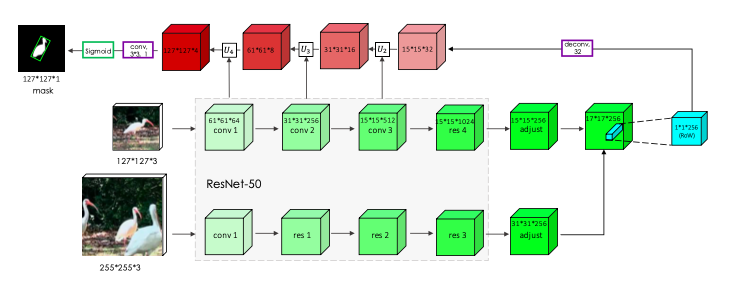
Summary
关于该文章,算是在 Siamese Tracker 基础上的改进,当然不限于文中所涉及到的两个跟踪算法,SiamFC 和 Siamese RPN。比如 MDNet 的几个基于分类的跟踪算法,也存在类似的目标表达方面的问题,即:Scale variation 。由于本文是基于 Siamese tracker 来做的,原始 Siamese tracker 的一些毛病,可能依然存在,如:heavy occlusion,fast motion 等问题。