今天虽然忙,但是还是看看论文吧,剩下的论文里面选了一个不太长的论文,是关于视觉追踪的,论文链接如下:
paper: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
本文基于区分训练的CNN,提出了新的视觉追踪算法,首先用大量的带真值的视频集预训练网络,得到了初步结果。本文的网络由共享层和特定域的多支路层组成,其中每个域都对应着单独的训练序列且每一个支路都有二元分类项来识别每个域的目标,当识别一个新的序列中的目标时,本文就在线通过组合预训练的共享层和一个新的二元分类层搭建一个新的网络。
Introduction
虽然CNNs在许多视觉任务上,比如分类,分割,检测等等,但是视觉追踪由于训练数据不够且没有专门设计的网络,并没有过多的被这个潮流影响,之前有的方法是直接将在大尺度数据集(如ImageNet)上预训练的网络转移过来,虽然也有效,但是毕竟两者还是有差距的。
视觉追踪的难度首先在于要基于有完全不同的特征的视频序列,去学习一个统一表达的网络,每个独立的序列都有不同的物体(Labels, Moving patterns, appearances)且每个序列都有特定的场景,灯光,动作模糊等等,至于训练网络就更加难了,因为同一种物体在一个序列里面是目标,但是在另一个序列里面可能是背景了,所以需要新的一个方法来捕捉序列相关的信息。
基于这个,本文提出了新的架构,叫 Multi-Domain Network (MDNet),提出的网络在最后面有彼此分开的特定域的支路,来实现二元分类,并在前面的层里面共享从各个序列中捕捉到的信息,MDNet的每个域都分开并迭代地训练,并上传到共享层里面去。
Multi-Domain Network (MDNet)
Network Architecture
提出的架构如下: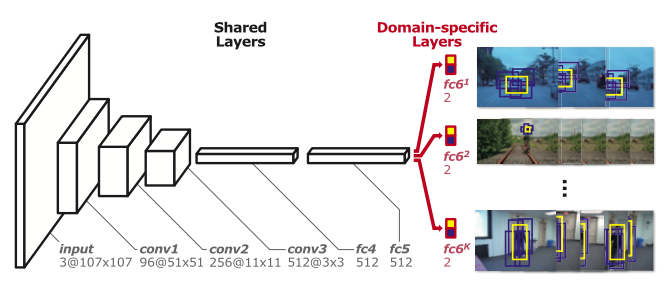
有三个卷积层、两个全连接层以及全连接层后面有K支网络对应于K个域(训练序列)。可以发现,该网络很简单,本文说这样设置的原因一是追踪不像物体识别,有很多类要分辨,而仅仅分辨出物体和背景就行了,第二,过深的网络往往会稀释空间信息,不太利于准确的定位物体,第三,追踪的物体一般很小,所以输入图也会较小,导致深度不深,最后,对于要在线上测试及训练的网络来说,小一点的网络显然更加有效。
Learning Algorithm
尽管域之间的物体和背景有很大差距,但是仍然会有一定相似性,比如对光照变化的鲁棒性,动作模糊,及放大缩小等因素,所以本文引入了一个多重域学习框架来从各个域中学习共有的信息。
Online Tracking using MDNet
从以上的多域学习算法之后,多支路网络就被一个单支路替换,用作测试序列,然后同时微调这个新的层和全连接层。
Tracking Control and Network Update
本文通过长期和短期的更新操作,同时考虑了追踪的两个互补的方面:鲁棒性和实用性。长期更新是每经过固定的长时间后,就用收集到的正向的例子的例子,而短期更新是没当识别错误之后,就更新一次。
Hard Minibatch Mining
负的例子的大多数都是不太重要且对于通过检测来追踪的办法来说是多余的,所以只有很少一部分转移的负例子对于训练器是有效的,对此本文将训练和测试部分交替执行来识别出硬的(hard)负例子。
Bounding Box Regression
由于高度抽象的特征和数据增强策略的原因(会采样目标周围的多重的正例子),本文的bounding box有时会不能紧贴目标周围,所以本文又增加了一个bounding box回归策略来提高准确性。