实验室给的关于商品识别的论文中,只剩下这篇关于从单张图片中提取循环特征的文章了,是2013年的CVPR,但还不知道和商品识别有什么关系,看看再说吧,链接如下:
Introduction
在现实生活中,一个很重要的认识就是我们对这个世界的大部分认识都是基于对共享或重复的结构的感知和识别,那么为了在这样的模式中捕捉到这种重现的本质的东西,本文使用了一种循环模式(Recurring Pattern), 来进行识别。
对于循环模式检测来说,主要有两种经典的方法:
Pairwise visual-word-matching: 在所有的物体间匹配一对一对的视觉的字(Visual Words)
Pairwise object-matching: 在一对物体间匹配特征点的相似性(Feature point correspondences)
但这两种方法都有局限性,后者虽然简单,但是不能完全利用所有的可利用信息,而前者同样也会有遗失特征点的可能性,但是要说这两种方法谁比较好,在缺乏全局的决策机制的情况下,现有的系统很难提供既灵活适应性又好的转化。
本文基于这个现状提出了一个可选择的联合优化框架(同时匹配视觉的字和物体两个维度),和一个贪心的随机化的可适应搜索程序(Greedy Randomized Adaptie Serarch Procedure(GRASP))来进行优化。
Approach
Formalization of Recurring Patterns
首先单个循环模式及其组成成分开始,由下图所示: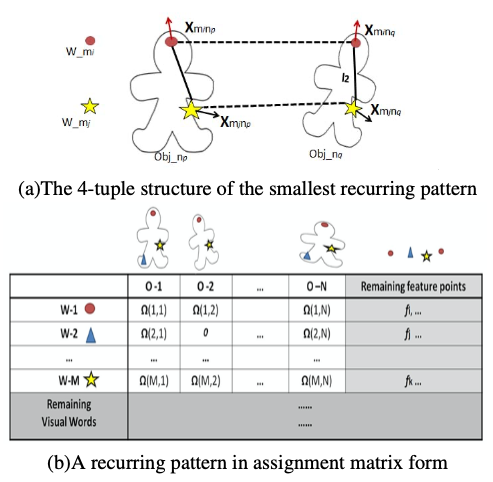
每个循环模式都至少有两个视觉物体,同样的,每个物体也都要求至少有两个不同的视觉字。这种定义一定程度上在最大化物体个数的同时能保证每个循环模式的唯一性。
本文根据每个模式,搭建了一个矩阵,如上图(b)。
Visual Word Extraction
给定一系列特征点$\mathbf{F}=\left\{f_{i} | i=1, \ldots, K\right\}$,那一个视觉字$W$就是$F$的一个子集,且$W$中的所有特征点都有很强的外表上的相似性,那么如果用$v_{i}$表示规范化的$f_{i}$,那么本文就能将两个特征之间的规范化相似性算法定义为:
那么每个$W$中的视觉字相似性为:
先在$F$找一个最大A值的点加入到$W$, 然后再找能够增加上式的点加入到$W$中,直到找不到了,就将现有的$W$作为一个视觉字。