上一本书的笔记做完之后,想了很多,笔记的作用一是记下自己的理解,方便日后观看,二是能防止自己走神,但是感觉之前做笔记的过程有些变味了,完全变成照抄,完全没有思考,所以这本书的笔记,会精简一些,但是也会尽量表达自己的想法,必要的地方做些摘抄,不过这本书是英文的,想写成中文笔记,本身也需要花费些精神呢。
这本书叫《Deep Learning-Bengio》,以下是笔记部分。
Deep Learning for AI
最开始AI是在一种纯粹的环境下诞生的,比如下棋,就是在一个规则固定且相对简单的环境中寻找制胜策略,这对于计算机来说自然是简单的,也不需要学习,但是这对于人类来说,却是相当抽象且困难。相反,人类日常的简单生活却是需要相当多的主观和直觉信息,这不是简单的几项规则能够概括的,那计算机又要怎样才能做到呢?
依赖硬编码知识的AI系统的瓶颈体现在系统需要能从原始数据中提取一定的模式,以获得自己的知识。这也就是机器学习。而机器学习的引进让机器能处理需要真实世界信息的问题,并做出近似主观的判断,出现了像逻辑回归(logistic regression)和朴素贝叶斯(naive Bayes)的方法。
但是这些算法不能知道那些特征是有用的,也不能注意到特征本身,如果给的不是一个格式化的报告,而是简单的原数据,算法也不能做出有用的判断。也很正常,数据的展示与结构本身就能对机器学习的效果有巨大的影响,如果特征提取设计的好,效果能大大提升,但是事实上,对于大部分的任务,人们都很难提取出正确的特征,不论是物体识别还是什么任务,人们都很难设计出怎样的像素才是对应的物体,更不用说各种各样的环境对物体表面的影响了。
其中一种处理办法就是使用机器学习去不仅仅学习数据表达与输出的对应,还要学习表达本身,这可以理解为表达学习(representation learning),这就取代了模式特征的设计阶段,且有时能比人类设计的特征更好,并增加了AI系统自主快速适应新任务的能力,大大减少了人们进行特征设计及研究的时间。
当人们设计特征的时候,人们往往倾向于寻找因素(Factors),即影响最终结果的因素,因素之间往往不是通过“乘”来实现的,而这些因素大多数不是直接观察到的,而是人们主观想到的,为多种多样的结果解释,比如演讲里面的演讲者的口音、年龄及性别等等。
但是有时因素太多,有时特征又太复杂,太抽象,就算是人也设计不出结构化的表达。
而深度学习,引入了表达学习,将表达以一种其他地,更简单的方式展示。比如下图: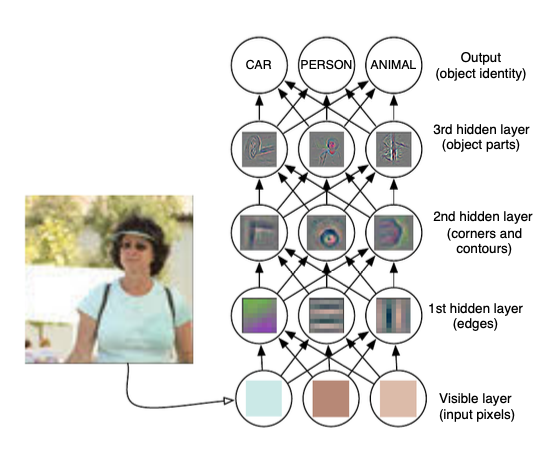
深度学习让计算机去学习一个多步(multi-step)的计算机程序,每层都能看成是计算机内存的一个状态。
总的来说,深度学习就是AI的一种,也是机器学习的一种,让计算机系统从经验和数据中提升,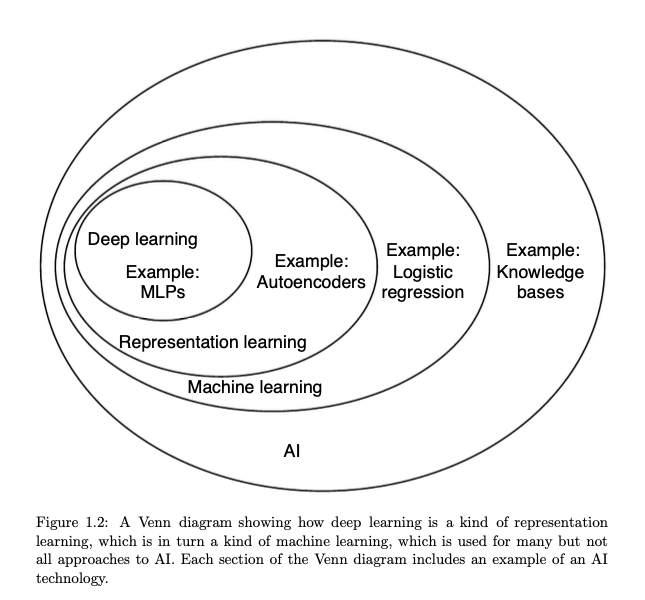
关系就像上面所形容的那样。
而数据的流动过程如下: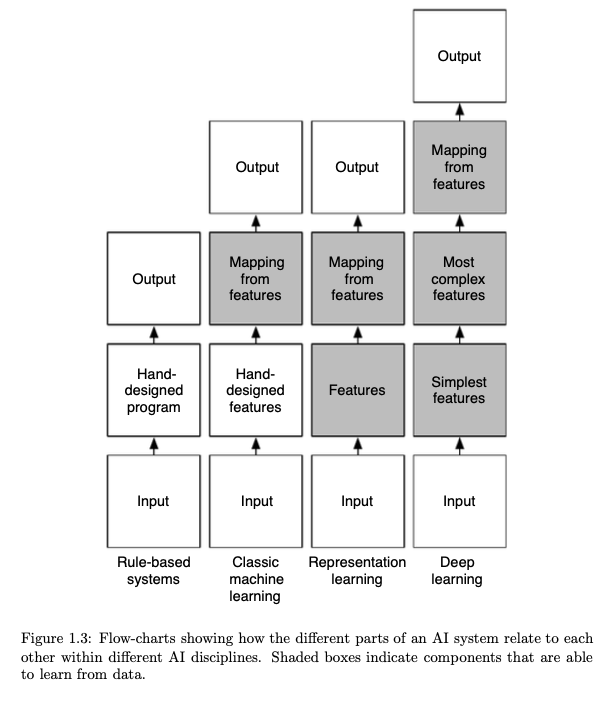
1.3 Historical Perspective and Neural Networks
现代的深度学习研究从先前的神经网络的研究获得了很多启示,其它的深度学习里面的研究还有概率建模和图形模型还有其它多种多样的学习工作。
1.5 Challenges for Future Research
虽然深度学习已经有这样的成功,但是现有科技仍然与当前的动物的信息处理能力和感知能力有巨大的差距,要了解到这些架构之后的规则就还需要更多基础科学的研究。
深度学习是很重要的工具,但它却不是AI的唯一解答。
而今后的深度学习的重要的突破口在于:
- 在无监督学习之后怎么应对基础的问题,比如说困难的推理和采样。
- 怎么构建并训练出更大,更具有适应性且可重构的复杂结构,以最大化在更大的数据集上训练的优点。
- 怎么提高深度学习算法的能力来弄清变化的潜在因素,或者搞清楚我们周围的这个世界。
Linear algebra
线性代数是数学的一个分支,线性代数的掌握对于理解深度学习即其算法很必要。
细节略
Probalility and Information Theory
概率论是用来描述不确定性规则的数学工具,它提供了量化不确定性的方法,以及推导新概率的公式。且概率论是许多科学和工程学科的基础工具。
细节略
Numerical Computation
机器学习算法通常需要大量的数值运算,这些算法并不是通过公式解析求得正确结果而是通过迭代更新解的估计值。包括线性方程组和最大最小值时的参数值。
4.1 Overflow and underflow
Underflow是指在计算机中接近0的数因为计算机架构的原因被取整到0,如果该数字之后被用于分母,那么就会出错,而Overflow则是大尺度的数字被估计为∞或-∞,在该数字上无法再进行有效的计算。
举个例子,以softmax函数为例:
如果c是一个很小的负数,那么exp(c)将会underflow,分母将为0,结果将出错,而若c是很大的正数,exp(c)将会overflow,这都将导致错误,当然可以用$\operatorname{softmax}(\boldsymbol{z}) \text { where } \boldsymbol{z}=\boldsymbol{x}-\max _{i} \boldsymbol{x}_{i}$来解决这个问题,
4.2 Poor conditioning
条件(conditioning)指的是一个方程在输入值轻微变化的时候,做出迅速的改变。这在进行科学运算的时候就会引出一些问题,因为四舍五入的误差会引起输出值的巨大的不同。
比如有一个方程为$f(\boldsymbol{x})=\boldsymbol{A}^{-1} \boldsymbol{x}$,当A为一个一个特征值分解,那么它的条件数(最大和最小特征值的大小之比)就是:
当这个数大的时候,矩阵的逆就对输入的偏差特别敏感。而且这个是矩阵本身的特性,当我们与真矩阵值相乘时,就会放大这个预先存在的错误。
4.3 Gradient-Based Optimization
大多数的学习算法都会涉及某种优化,而优化则是通过改变x,来最大化或最小化函数值。这个函数值就是目标函数(objective function),若是最小化,也可以叫它损失函数(cost/loss/error function),通过在使得函数值最大或最小的x值旁边加上,即$x^{}=\arg \min f(\boldsymbol{x})$。
通过求导数,可以知道函数在一个点的倾斜度,它表示了y会对于x的小变化做出多少倍的反应,所以导数能够被用来最小化一个函数,因为它告诉了应该怎么改变x值,才能得到更优化的y值。但是当函数值比周围点的函数值都小时,就到达了局部最大(小)值,就很难通过缓慢移动来提升函数值了。
除此之外,深度学习也很容易走到局部最小值而非全局最优值,在非常平的地方也会出现问题,或者在很平的地方周围出现很多鞍点,特别是当输入是多维的时候。所以如下图: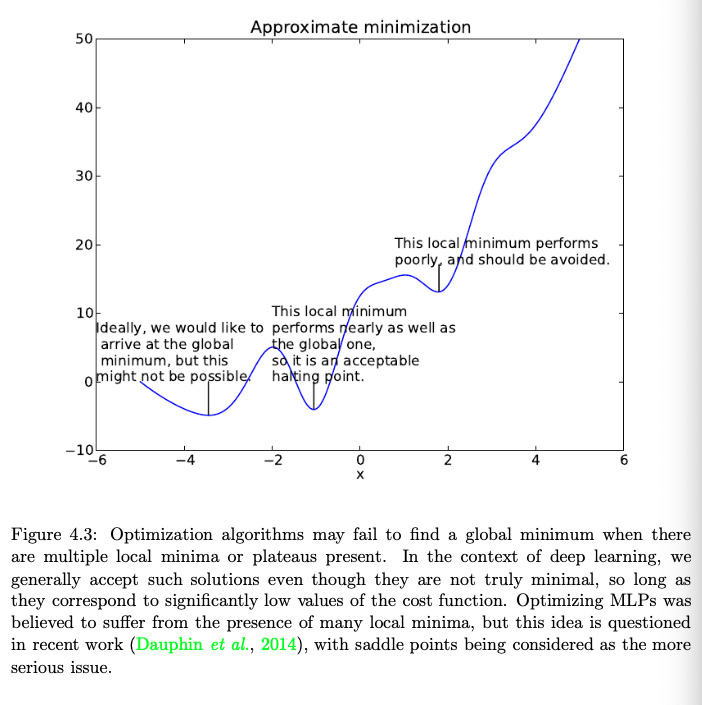
当局部极值过多,对于深度学习,有时候也只能接受,只要它和最值接近。
当优化方程有众多输入:$f : \mathbb{R}^{n} \rightarrow \mathbb{R}$,那就必须要用到偏导数了,它显示了单个变量在某点对函数值的影响,而一个函数f的梯度则是包含了函数所有偏导数的矩阵,表示为$\nabla_{\boldsymbol{x}} f(\boldsymbol{x})$,其中关键点就是梯度里面的每个元素值都是0。
在方向u(单位向量)上的方向导数,是函数f在方向u上的倾斜度。也就是说函数$f(\boldsymbol{x}+\alpha \boldsymbol{u})$关于α的导数,在α为0时,使用链式法则,可以得到$\boldsymbol{u}^{\top} \nabla_{\boldsymbol{x}} f(\boldsymbol{x})$。
为了最小化f,就是要找到f下降最快的方向:
其中$\theta$是u和梯度的夹角,代替$|\boldsymbol{u}|_{2}=1$,忽视不依赖于u的元素,方程就简化到了$\min _{u} \cos \theta$,当u与梯度相反时,达到最小值,也就是说,梯度直接指向上坡,而负梯度直接指向下坡,沿着负梯度方向移动f就能减少f值,这就是最速下降法或者说梯度下降法(steepest descent or gradient descent),最陡的下降就到了新的点:
其中$\epsilon$就是步长大小,有很多方法可以设置,比如将之设置为小的常量,有时也可以解决由于步长设置而引起的梯度消失问题,或者根据$f\left(\boldsymbol{x}-\epsilon \nabla_{\boldsymbol{x}} f(\boldsymbol{x})\right)$选择一系列的$\epsilon$,并选择最小函数值的结果,这一策略叫作线搜索。
当梯度的每一个元素都变为0,或者趋于0时,下降就收敛了,在某些例子中,可以直接求解方程$\nabla_{\boldsymbol{x}} f(\boldsymbol{x})=0$,直接就跳到关键点,以避免不停的迭代。
求得导数的导数有时候也会有所用处,也就是二阶导数,比如$\frac{\partial^{2}}{\partial x_{i} \partial x_{j}} f$就是对于,f在$x_{j}$上的导数在$x_{i}$上的导数,导数的顺序可以交换,即$\frac{\partial^{2}}{\partial x_{i} \partial x_{j}} f=\frac{\partial^{2}}{\partial x_{j} \partial x_{i}} f$。
二阶导数能告诉我们,当改变输入时,一阶导数是怎么改变的,也就能用来判断一个关键点是一个局部极大值,局部最小值还是一个鞍点。因为这些点都$f^{\prime}(x)=0$,但是若$f^{\prime \prime}(x)>0$,则是局部最小值,若$f^{\prime \prime}(x)<0$,则为局部最大值,但是若$f^{\prime \prime}(x)=0$,结果有可能是鞍点也有可能是一片平的区域。
记录二阶导数的矩阵是黑塞矩阵(Hessian matrix,又译作海森矩阵、海塞矩阵或海瑟矩阵等),可以记录为:$$
\boldsymbol{H}(f)(\boldsymbol{x})_{i, j}=\frac{\partial^{2}}{\partial x_{i} \partial x_{j}} f(\boldsymbol{x})
f(\boldsymbol{x})=f\left(\boldsymbol{x}_{0}\right)+\left(\boldsymbol{x}-\boldsymbol{x}_{0}\right)^{\top} \nabla_{\boldsymbol{x}} f\left(\boldsymbol{x}_{0}\right)+\frac{1}{2}\left(\boldsymbol{x}-\boldsymbol{x}_{0}\right)^{\top} H(f)\left(\boldsymbol{x}_{0}\right)\left(\boldsymbol{x}-\boldsymbol{x}_{0}\right)
\boldsymbol{x}^{*}=\boldsymbol{x}_{0}-H(f)\left(\boldsymbol{x}_{0}\right)^{-1} \nabla_{\boldsymbol{x}} f\left(\boldsymbol{x}_{0}\right)
\begin{array}{c}{\nabla_{\mathbf{w}} \operatorname{MSE}_{\text {train }}=0} \\ {\Rightarrow \nabla_{\mathbf{w}} \frac{1}{m}\left|\hat{\mathbf{y}}^{(\text {train })}-\mathbf{y}^{(\text {train })}\right|_{2}^{2}=0} \\ {\Rightarrow \frac{1}{m} \nabla_{\mathbf{w}}\left|\mathbf{X}^{(\text {train })} \mathbf{w}-\mathbf{y}^{(\text {train })}\right|_{2}^{2}=0}\end{array}
\begin{array}{c}{\Rightarrow \nabla_{\mathbf{w}}\left(\mathbf{X}^{(\text {train })} \mathbf{w}-\mathbf{y}^{(\text {train })}\right)^{\top}\left(\mathbf{X}^{(\text {train })} \mathbf{w}-\mathbf{y}^{(\text {train })}\right)=0} \\ {\Rightarrow \nabla_{\mathbf{w}}\left(\mathbf{w}^{\top} \mathbf{X}^{\text {(train) }} \mathbf{X}^{(\text {train })} \mathbf{w}-2 \mathbf{w}^{\top} \mathbf{X}^{(\text {train }) \top} \mathbf{y}^{(\text {train })}+\mathbf{y}^{(\text {train }) \top} \mathbf{y}^{(\text {train })}\right)=0} \\ {\Rightarrow 2 \mathbf{X}^{(\text {train }) \top} \mathbf{X}^{(\text {train })} \mathbf{w}-2 \mathbf{X}^{(\text {train }) \top} \mathbf{y}^{(\text {train })}=0} \\ {\Rightarrow \mathbf{w}=\left(\mathbf{X}^{(\text {train }) \top} \mathbf{X}^{(\text {train })}\right)^{-1} \mathbf{X}^{(\text {train })} \mathbf{y}^{(\text {train })}}\end{array}
\hat{\theta}_{n}=g\left(x_{1}, \ldots, x_{n}\right)
\operatorname{bias}\left(\hat{\theta}_{n}\right)=\mathbb{E}\left(\hat{\theta}_{n}\right)-\theta
\operatorname{Var}[\hat{\theta}]=\mathbb{E}\left[\hat{\theta}^{2}\right]-\mathbb{E}[\hat{\theta}]^{2}
\operatorname{se}(\hat{\theta})=\sqrt{\operatorname{Var}[\theta]}
\begin{aligned} \mathrm{MSE} &=\mathbb{E}\left[\hat{\theta}_{n}-\theta\right]^{2} \\ &=\operatorname{Bias}\left(\hat{\theta}_{n}\right)^{2}+\operatorname{Var}\left[\hat{\theta}_{n}\right] \end{aligned}
\lambda|\theta|^{2}
p(\theta | \boldsymbol{x})=\frac{p(\boldsymbol{x} | \theta) p(\theta)}{p(\boldsymbol{x})}
\underset{f}{\arg \min } \mathbb{E}\left[|Y-f(X)|^{2}\right]=\mathbb{E}[Y | X]
p=\operatorname{softmax}(a) \Longleftrightarrow p_{i}=\frac{e^{a_{i}}}{\sum_{j} e^{a_{j}}}
P\left(Y_{1}, Y_{2}, \ldots Y_{k} | x\right)=\prod_{i=1}^{k} P\left(Y_{i} | x\right)
\theta \leftarrow \theta-\epsilon \frac{\partial L\left(f_{\theta}(x), y\right)}{\partial \theta}-\epsilon \lambda \theta
\frac{\partial C(g(\theta))}{\partial \theta}=\frac{\partial C(g(\theta))}{\partial g(\theta)} \frac{\partial g(\theta)}{\partial \theta}
\frac{\partial C(g(\theta))}{\partial \theta}=\sum_{i} \frac{\partial C(g(\theta))}{\partial g(\theta)} \frac{\partial g_{i}(\theta)}{\partial \theta}
\frac{\partial u_{N}}{\partial u_{i}}=\sum_{\text {mpaths } u_{1} \cdots u_{k} ; k_{1}=i, k_{n}=N} \prod_{j=2}^{n} \frac{\partial u_{k_j}}{\partial u_{k_{j-1}}
f=f_{T} \circ f_{T-1} \circ \ldots f_{2} \circ f_{1}
f^{\prime}=f_{T}^{\prime} f_{T-1}^{\prime} \ldots f_{2}^{\prime} f_{1}
f^{\prime}=\frac{\partial f(x)}{\partial x}
f_t^{\prime}=\frac{\partial f_t (a_t)}{\partial a_t}
\boldsymbol{a}_{t}=f_{t-1}\left(f_{t-2}\left(\ldots f_{2}\left(f_{1}(\boldsymbol{x})\right)\right)\right)
s_{t}=F_{\theta}\left(s_{t-1}, x_{t}\right)
o_{t}=g_{\omega}\left(s_{t}\right)
\frac{\partial L_{T}}{\partial \theta}=\sum_{t \leq T} \frac{\partial L_{T}}{\partial s_{T}} \frac{\partial s_{T}}{\partial s_{t}} \frac{\partial F_{\theta}\left(s_{t-1} x_{t}\right)}{\partial \theta}
\frac{\partial s_{T}}{\partial s_{t}}=\frac{\partial s_{T}}{\partial s_{T-1}} \frac{\partial s_{T-1}}{\partial s_{T-2}} \ldots \frac{\partial s_{t+1}}{\partial s_{t}}
p(\mathbf{x})=\Pi_{i} p\left(\mathbf{x}_{i} | P a_{\mathcal{G}}\left(\mathbf{x}_{i}\right)\right)
p\left(\mathrm{t}_{0}, \mathrm{t}_{1}, \mathrm{t}_{2}\right)=p\left(\mathrm{t}_{0}\right) p\left(\mathrm{t}_{1} | \mathrm{t}_{0}\right) p\left(\mathrm{t}_{2} | \mathrm{t}_{1}\right)
\tilde{p}(\mathbf{x})=\Pi_{\mathcal{C} \in \mathcal{G}} \phi(\mathcal{C})
p(\mathbf{x})=\frac{1}{Z} \tilde{p}(\mathbf{x})
Z=\int \tilde{p}(\mathbf{x}) d \mathbf{x}
z=\int_{-\infty}^{\infty} x^{2} d x
\tilde{p}(\mathbf{x}) = exp(-E(\mathbf{x}))
\forall \boldsymbol{x}^{\prime}, \pi\left(\boldsymbol{x}^{\prime}\right)=\sum_{\boldsymbol{x}} T\left(r v x^{\prime} | \boldsymbol{x}\right) \pi(\boldsymbol{x})
T \pi=\pi
\boldsymbol{h}=f(\boldsymbol{x})=\underset{\boldsymbol{h}}{\arg \min } L(g(\boldsymbol{h}), \boldsymbol{x}))+\lambda \Omega(\boldsymbol{h})
其中($\alpha h_{i}$有一个Student-t 先验密度)以及KL-散度惩罚:
$$-\sum_{i}\left(t \log h_{i}+(1-t) \log \left(1-h_{i}\right)\right)$$
其中对于$h_{i} \in(0,1)$,有一个目标稀疏层次t,通过一个Sigmoid 非线性。
4.收缩自动编码器,显式的惩罚$\left|\frac{\partial \boldsymbol{h}}{\partial \boldsymbol{x}}\right|_{F}^{2}$项,即向量$\frac{\partial h_{i}(\boldsymbol{x})}{\partial \boldsymbol{x}}$的平方范数的总和(每个值指示每个隐藏单元$h_i$对x的变化有多少响应,以及该单元对x的哪个变化方向最敏感,特别是x附近)。 由于这种正则化惩罚,自动编码器被称为收缩,因为从输入x到表示h的映射是收缩的,即在所有方向上都具有小的导数。
- 对注入的噪声的鲁棒性:如果在输入或隐藏单元中注入了噪声,或者有些输入缺失了,而要求神经网络重建干净完整的输入,那么它将不能简单地学习 identify function。它必须捕获数据分布的结构,以便最佳地执行此重构。这种自动编码器称为降噪自动编码器。
- 先验对represention的压力:一种有趣的将正则化的概念归纳应用representation的方法,是在自动编码器的代价函数中引入对数优先项它捕获了以下假设:我们希望找到一种具有简单分布的represention,或者至少要找到一种比原始数据分布更简单的表示形式。在所有编码函数f中,我们想选择一个
- 可以(轻松)反转,这是通过最小化一些重建损失来实现的。
- 产生分布“更简单”的represention h,即,与原始训练分布本身相比,可以用较少的容量捕获它们。
10.1.2 Representational Power, Layer Size and Depth
上述的关于自动编码器的描述中,没有任何要求,限制编码器或解码器一定要浅,但是在有关该主题的文献中,大多数训练过的的自动编码器具有单个隐藏层,该隐藏层即是表示层也是code。
首先,我们通过单个隐层神经网络的一般通用的逼近能力知道,足够大的隐层可以以给定的精度表示任何函数。这种观察证明了overcomplete的自动编码器:为了表示足够丰富的分布,在中间表示层中可能需要许多隐藏单元。我们还知道,主成分分析(PCA)对应于一个undercomplete的自动编码器,且没有中间非线性,并且PCA只能捕获一组在空间各处方向均相同的变量。
其次,还多次报道训练深度神经网络,特别是深度自动编码器(即具有深度编码器和深度解码器)比训练浅层神经网络更加困难。这实际上是,对贪婪的分层无监督预训练过程进行初始工作的动机,如下节所述,通过该过程,我们只需要训练一系列浅层自动编码器即可初始化深层自动编码器。早期研究表明,如果训练得当,这种深层自动编码器会比相应的浅层或线性自动编码器产生更好的压缩效果。正如第14.3节中讨论的那样,更深的架构在某些情况下(在计算和统计方面),会比较浅的体系结构指数性更有效。但是,由于我们可以通过训练和堆叠浅层网络来有效地预训练深层网络,因此考虑单层自动编码器变得很有趣。
10.1.3 Reconstruction Distribution
当损失L是简单的平方重建误差时,上述“部分”(编码器函数f,解码器函数g,重建损失L)是有意义的,但是在许多情况下,这是不合适的,例如,当x是一个离散变量的向量或当$P(\boldsymbol{x} | \boldsymbol{h})$不能很好地由高斯分布估计时。就像其他类型的神经网络中一样(从前馈神经网络开始),将loss L定义为对某些目标随机变量的负对数可能性(negative log-likelihood)很方便。
因此,我们能产生解码函数$g(h)$的意识,来解码$P(\boldsymbol{x} | \boldsymbol{h})$分布。同样的,我们能生成编码函数$f(x)$的意识,如同下图所示。我们用它来捕获这样一个事实,即噪声在representation h的层次注入,现在将其视为潜在变量。这种推论对于可变自动编码器和广义随机网络的发展至关重要。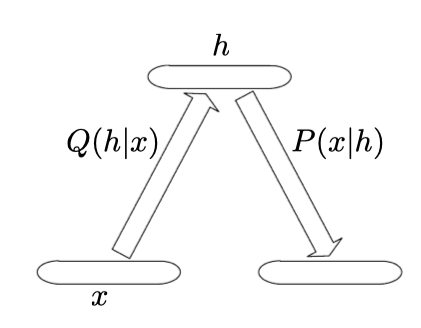
随机自动编码器的基本方案,其中编码器和解码器都不是简单的函数,而是包含一些噪声注入,这意味着它们的输出可以看作是从分布中采样,$Q(h | x)$用于编码器,$P(x | h)$用于解码器。RBM是一种特殊情况,其中$P = Q$,但通常这两个分布不一定是与唯一联合分布$P(x, h)$兼容的条件分布。
10.2 Linear Factor Models
很早就有研究,去发现相互之间具有简单联合分布的解释性因子,并且是在因素和数据之间的关系呈线性关系的情况下首次进行探索的,即,我们假设数据由如下步骤生成。首先,对实际价值因素进行抽样:
然后给定因子,对实值可观察变量进行采样:
其中噪声是典型的高斯和对角线。
正如下图中所示: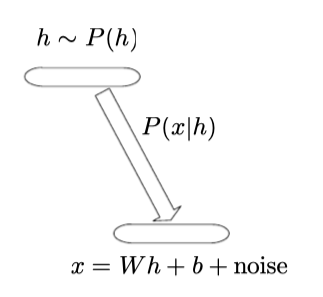
上图是线性因子模型的基本框架,其中我们假设一个观察到的数据向量x是通过一个隐参数h的线性组合而来,再加上噪声。
10.2.1 Probabilistic PCA and Factor Analysis
概率PCA(主成分分析)和因子分析都是上述两个等式的特例,并且仅在对先验分布和噪声分布进行选择时有所不同。